The function dscore() function estimates the D-score,
a numeric score that measures child development, from PASS/FAIL
observations on milestones.
dscore(
data,
items = names(data),
xname = "age",
xunit = c("decimal", "days", "months"),
prepend = NULL,
key = NULL,
itembank = dscore::builtin_itembank,
metric = c("dscore", "logit"),
prior_mean = NULL,
prior_sd = NULL,
transform = NULL,
qp = -10:100,
population = NULL,
dec = c(2L, 3L),
relevance = c(-Inf, Inf)
)
dscore_posterior(
data,
items = names(data),
xname = "age",
xunit = c("decimal", "days", "months"),
prepend = NULL,
key = NULL,
itembank = dscore::builtin_itembank,
metric = c("dscore", "logit"),
prior_mean = NULL,
prior_sd = NULL,
transform = NULL,
qp = -10:100,
population = NULL,
dec = c(2L, 3L),
relevance = c(-Inf, Inf)
)Arguments
- data
A
data.framewith the data. A row collects all observations made on a child on a set of milestones administered at a given age. The function calculates a D-score for each row. Different rows correspond to different children or different ages.- items
A character vector containing names of items to be included into the D-score calculation. Milestone scores are coded numerically as
1(pass) and0(fail). By default, D-score calculation is done on all items found in the data that have a difficulty parameter under the specifiedkey.- xname
A string with the name of the age variable in
data. The default is"age".- xunit
A string specifying the unit in which age is measured (either
"decimal","days"or"months"). The default ("decimal") means decimal age in years.- prepend
Character vector with column names in
datathat will be prepended to the returned data frame. This is useful for copying columns from data into the result, e.g., for matching.- key
A string that selects a subset in the itembank that makes up the key, the set of difficulty estimates from a fitted Rasch model. The built-in keys are:
"gsed2212"(default),"gsed2208"(deprecated),"gsed2206"(deprecated),"gsed1912","lf2206","sf2206","gcdg", and"dutch". Since version 1.5.0, thekey = "gsed"selects the latest key starting with the string "gsed". Usekey = ""to use all item names, which should only be done if there are no duplicate itemnames in the itembank.- itembank
A
data.framewith columnskey,item,tau,instrument,domain,mode,numberandlabel. Only columnsitemandtauare required. The function usesdscore::builtin_itembankby default.- metric
A string, either
"dscore"(default) or"logit", signalling the metric in which ability is estimated.- prior_mean
A string specifying where the mean of the prior for the D-score calculation should come from. It could be a column name in
data(when you want your own prior for every row), but normally this is one of the keywords".dutch",".gcdg"or".phase1". The default depends on thekey. Ifkey == "dutch"thenprior_mean = ".dutch". The choiceprior_mean = ".dutch"calculatesprior_meanfrom the Count model coded indscore:::count_mu_dutch()). Ifkeyis #'"gcdg","gsed1912","gsed2206","lf2206"or"sf2206"thenprior_mean = ".gcdg". This setting calculates an age-dependent prior mean internally according to functiondscore:::count_mu_gcdg(). In other cases,prior_mean = ".phase1"which uses the functiondscore:::count_mu_phase1(). Normally, you should not touch this parameter, but feel free to useprior_meanto override the automatic choices.- prior_sd
A string specifying a column name in
datawith the standard deviation of the prior for the D-score calculation. If not specified, the standard deviation is taken as 5 for every row.- transform
Vector of length 2, signalling the intercept and slope respectively of the linear transform that converts an observation in the logit scale to the the D-score scale. Only needed if
metric == "logit".- qp
Numeric vector of equally spaced quadrature points. This vector should span the range of all D-score values. The default (
qp = -10:100) is suitable for age range 0-4 years.- population
A string describing the population. Currently supported are
"phase1"(default),"dutch","gcdg".- dec
A vector of two integers specifying the number of decimals for rounding the D-score and DAZ, respectively. The default is
dec = c(2L, 3L).- relevance
A numeric vector of length with the lower and upper bounds of the relevance interval. The procedure calculates a dynamic EAP for each item. If the difficulty level (tau) of the next item is outside the relevance interval around EAP, the procedure ignore the score on the item. The default is
c(-Inf, +Inf)does not ignore scores.
Value
The dscore() function returns a data.frame with nrow(data) rows.
Optionally, the first block of columns can be specified by prepend
are copied from data. The second block consists of the
following columns:
| Name | Label |
a | Decimal age |
n | Number of items with valid (0/1) data |
p | Percentage of passed milestones |
d | Ability estimate, mean of posterior |
sem | Standard error of measurement, standard deviation of the posterior |
daz | D-score corrected for age, calculated in Z-scale |
The dscore_posterior() function returns a data frame with
nrow(data) rows and length(qp) plus prepended columns with the
density at each quadrature point. A row vector representes the full
posterior ability distribution. If no valid responses are found,
dscore_posterior() returns the prior density. Versions prior to
1.8.5 returned a matrix (instead of a data.frame). Code that depends on
the result being a matrix may break and needs to be adapted.
Details
The algorithm is based on the method by Bock and Mislevy (1982). The method uses Bayes rule to update a prior ability into a posterior ability.
The item names should correspond to the "gsed" lexicon.
A key is defined by the set of estimated item difficulties.
| Key | Model | Quadrature | Instruments | Direct/Caregiver | Reference |
"dutch" | 75_0 | -10:80 | 1 | direct | Van Buuren, 2014/2020 |
"gcdg" | 565_18 | -10:100 | 14 | direct | Weber, 2019 |
"gsed1912" | 807_17 | -10:100 | 20 | mixed | GSED Team, 2019 |
"gsed2206" | 818_17 | -10:100 | 22 | mixed | GSED Team, 2022 |
"gsed2208" | 818_6 | -10:100 | 22 | mixed | GSED Team, 2022 |
"gsed2212" | 818_6 | -10:100 | 22 | mixed | GSED Team, 2022 |
"lf2206" | 155_0 | -10:100 | 1 | direct | GSED Team, 2022 |
"sf2206" | 139_0 | -10:100 | 1 | caregiver | GSED Team, 2022 |
As a general rule, one should only compare D-scores
that are calculated using the same key and the same
set of quadrature points. For calculating D-scores on new data,
the advice is to use the default, which currently links to
"gsed2212".
The default starting prior is a mean calculated from a so-called
"Count model" that describes mean D-score as a function of age. The
Count models are stored as internal functions
dscore:::count_mu_phase1(), dscore:::count_mu_gcdg() and
dscore:::count_mu_dutch(). The spread of the starting prior
is 5 D-score points around this mean D-score, which corresponds to
approximately 1.5 to 2 times the normal spread of child of a given age. The
starting prior is thus somewhat informative for low numbers of
valid items, and uninformative for large number of items (say >10 items).
References
Bock DD, Mislevy RJ (1982). Adaptive EAP Estimation of Ability in a Microcomputer Environment. Applied Psychological Measurement, 6(4), 431-444.
Van Buuren S (2014). Growth charts of human development. Stat Methods Med Res, 23(4), 346-368. https://stefvanbuuren.name/publication/van-buuren-2014-gc/
Weber AM, Rubio-Codina M, Walker SP, van Buuren S, Eekhout I, Grantham-McGregor S, Caridad Araujo M, Chang SM, Fernald LCH, Hamadani JD, Hanlon A, Karam SM, Lozoff B, Ratsifandrihamanana L, Richter L, Black MM (2019). The D-score: a metric for interpreting the early development of infants and toddlers across global settings. BMJ Global Health, BMJ Global Health 4: e001724. https://gh.bmj.com/content/bmjgh/4/6/e001724.full.pdf
See also
Examples
data <- data.frame(
id = c("Jane", "Martin", "ID-3", "No. 4", "Five", "6",
NA_character_, as.character(8:10)),
age = rep(round(21 / 365.25, 4), 10),
ddifmd001 = c(NA, NA, 0, 0, 0, 1, 0, 1, 1, 1),
ddicmm029 = c(NA, NA, NA, 0, 1, 0, 1, 0, 1, 1),
ddigmd053 = c(NA, 0, 0, 1, 0, 0, 1, 1, 0, 1)
)
items <- names(data)[3:5]
# third item is not part of default key
get_tau(items)
#> ddifmd001 ddicmm029 ddigmd053
#> 8.61 8.47 NA
# calculate D-score
dscore(data)
#> a n p d sem daz
#> 1 NA 0 NA NA NA NA
#> 2 NA 0 NA NA NA NA
#> 3 0.0575 1 0.0 6.61 2.763004 -2.019
#> 4 0.0575 2 0.0 5.60 2.459750 -2.235
#> 5 0.0575 2 0.5 9.09 1.695326 -1.447
#> 6 0.0575 2 0.5 9.09 1.695326 -1.447
#> 7 0.0575 2 0.5 9.09 1.695326 -1.447
#> 8 0.0575 2 0.5 9.09 1.695326 -1.447
#> 9 0.0575 2 1.0 15.30 3.851173 0.277
#> 10 0.0575 2 1.0 15.30 3.851173 0.277
# prepend id variable to output
dscore(data, prepend = "id")
#> id a n p d sem daz
#> 1 Jane NA 0 NA NA NA NA
#> 2 Martin NA 0 NA NA NA NA
#> 3 ID-3 0.0575 1 0.0 6.61 2.763004 -2.019
#> 4 No. 4 0.0575 2 0.0 5.60 2.459750 -2.235
#> 5 Five 0.0575 2 0.5 9.09 1.695326 -1.447
#> 6 6 0.0575 2 0.5 9.09 1.695326 -1.447
#> 7 <NA> 0.0575 2 0.5 9.09 1.695326 -1.447
#> 8 8 0.0575 2 0.5 9.09 1.695326 -1.447
#> 9 9 0.0575 2 1.0 15.30 3.851173 0.277
#> 10 10 0.0575 2 1.0 15.30 3.851173 0.277
# prepend all data
# dscore(data, prepend = colnames(data))
# calculate full posterior
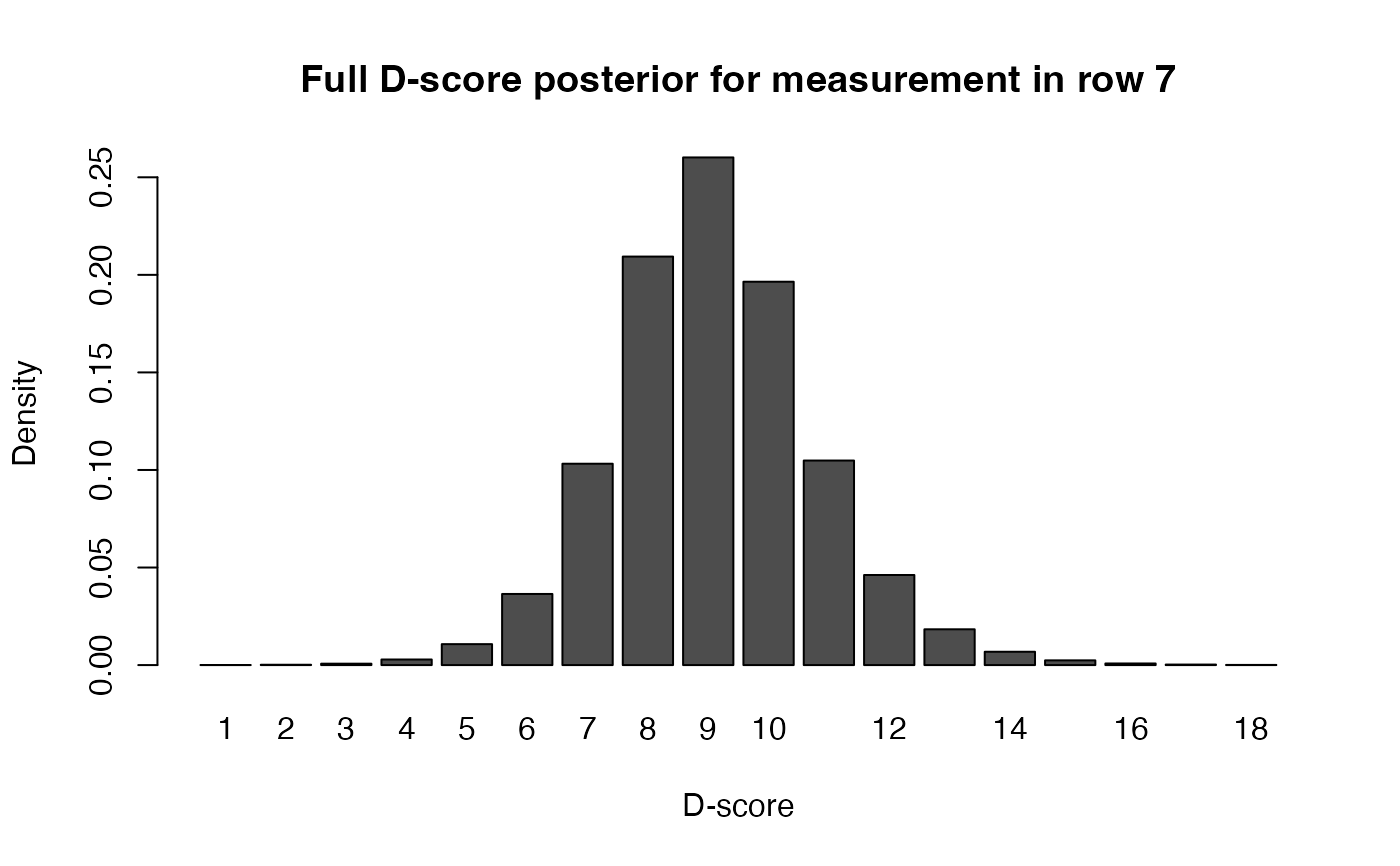
p <- dscore_posterior(data)
# check that rows sum to 1
rowSums(p)
#> [1] 0.9999992 0.9999992 1.0000000 1.0000000 1.0000000 1.0000000 1.0000000
#> [8] 1.0000000 1.0000000 1.0000000
# plot posterior for row 7
barplot(as.matrix(p[7, 12:29]), names = 1:18,
xlab = "D-score", ylab = "Density",
main = "Full D-score posterior for measurement in row 7")